BASE1<-read.csv("futbol.csv",sep=",",encoding = "latin1")
#Base delimitada al Bacelona
BASE1a<-subset(BASE1,squad=="Barcelona")
#librerías de graficación
library(ggplot2) #Gráficos
library(RColorBrewer) #Colores de los gráficos
library(plyr) #arrange()
library(forcats) #fct_rev()5 Gráficos de distribuciones de frecuencias
5.1 Distribuciones de frecuencia de variables nominales
La distribución de frecuencia de las variables nominales se realiza por medio de un gráfico de barras horizontales, con los mismos estándares del gráfico de barras de valores de variables cuantitativas, según niveles de variables cualitativas. A continuación se presenta la distribución de la variable pie dominante en los jugadores del Barcelona
df<-data.frame(table(BASE1a$foot))
df<-arrange(df, desc(df[,2]))
names(df)<-c("Pie","frecuencia")
df Pie frecuencia
1 right 16
2 left 10
3 both 1ggplot(data = df, aes( y=Pie, x=frecuencia)) +
geom_col(fill="#1F78B4", width=0.5) +
labs(x = "Frecuencia",
y = "Pie",
title = "Distribución del Pie dominante, según jugadores. FC Barcelona 2019-2020.")+
scale_y_discrete(labels=c("right" = "derecho", "left" = "izquierdo", "both"="ambos"))+
theme(panel.background = element_rect(fill='transparent', color="black"))
5.2 Distribuciones de frecuencia de variables ordinales y discretas
En las variables discretas se suele utilizar un gráfico de barras o bastones verticales. En función de esto, se le debe proporcioar a ggplot una base de datos con una columna de valores de la variable y otra con las frecuencias de estos valores.
En estos gráficos se debe recordar el eje x debe presentar todos los niveles, aunque estos tengan frecuencia 0. Una forma de garantizar que esta característica sea considerada por ggplot es la siguiente:
- En el caso de variables ordinales se debe convertir a factor la variable ordinal, e indicar en los niveles todos los niveles posibles aunque no hayan sido observados.
- En el caso de variables discretas se debe asegurar que la columna de valores de la variable observada sea numérica.
En el caso de la distribución de frecuencias de los goles del Barcelona, se tiene el gráfico adjunto.
df<-data.frame(table(BASE1a$goals))
#Convertir niveles de goles en una variable numérica
df[,1]<-as.numeric(as.character(df$Var1))
names(df)<-c("goles","frecuencia")
ggplot(data = df, aes( x=goles, y=frecuencia)) +
geom_col(fill="#1F78B4") +
labs(x = "Goles",
y = "Frecuencia",
title = "Distribución de los goles, según jugadores. FC Barcelona 2019-2020.")+
theme(panel.background = element_rect(fill='transparent', color="black"))
5.3 Distribuciones de frecuencia de variables continuas
En las variables continuas se utiliza un gráfico denominado histograma.En este caso no se necesita construir una base de datos preliminar, ya que se utilizan todos los datos de la variable para la graficación.
#Gráfico
ggplot(data = BASE1, aes( x=height)) +
geom_histogram(fill="#1F78B4",bins=10, closed="right",boundary = min(BASE1$height)) +
labs(size= "",
x = "Altura (cm)",
y = "Total de jugadores",
title = "Total de jugadores según altura. Barcelona y Real Madrid 2019-2020.")+
theme(panel.background = element_rect(fill='transparent', color="black"))
Otra forma de presentar la distribución de una variable continua es por medio de un polígono de frecuencias.
#Valores
ggplot(data = BASE1, aes( x=height)) +
geom_histogram(fill="#1F78B4",bins=10, closed="right",boundary = min(BASE1$height)) +
geom_freqpoly(colour="#E31A1C", size=1.5, bins=10, closed="right",boundary = min(BASE1$height)) +
labs(size= "",
x = "Altura (cm)",
y = "Total de jugadores",
title = "Total de jugadores según altura. Barcelona y Real Madrid 2019-2020.")+
theme(panel.background = element_rect(fill='transparent', color="black"))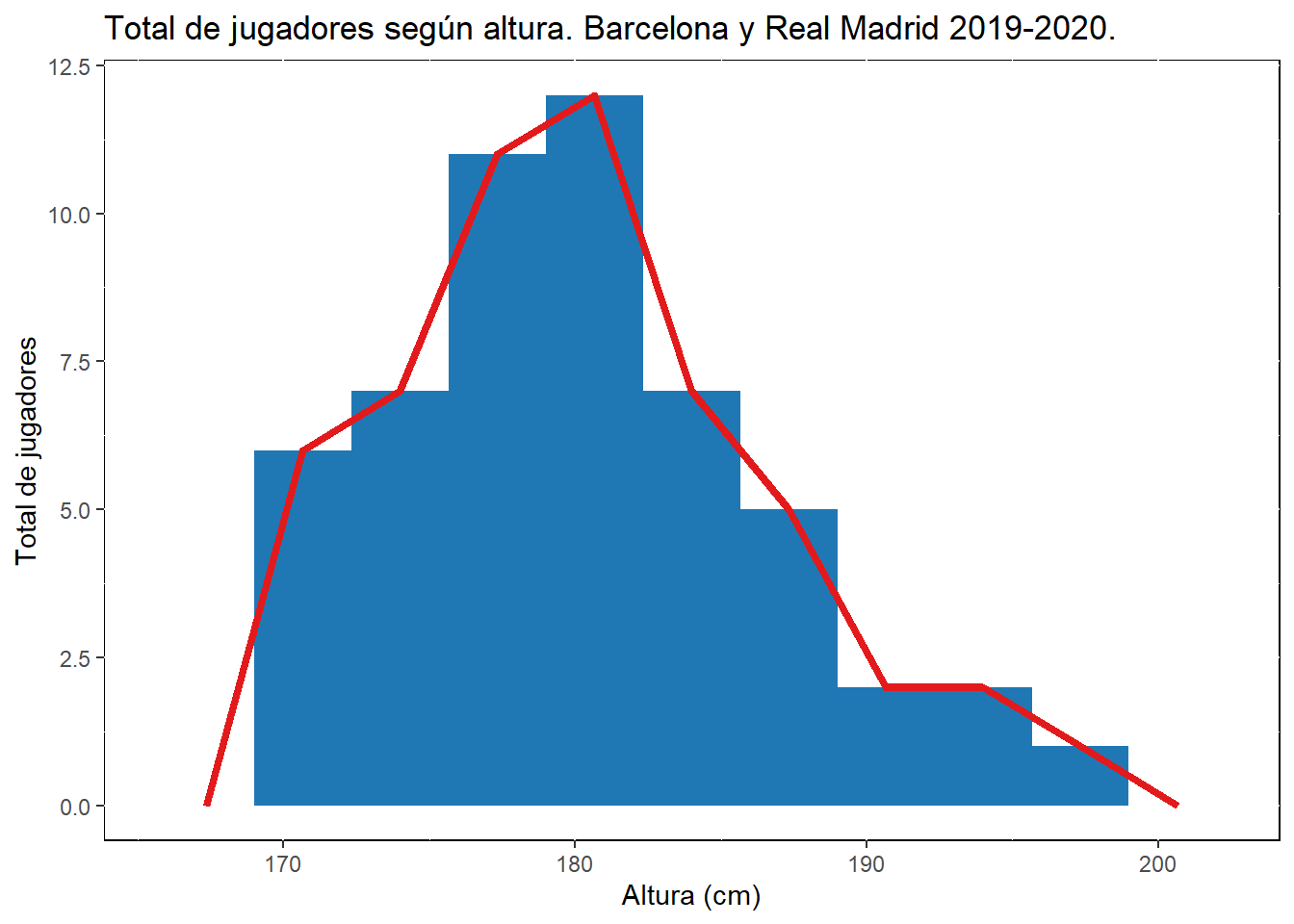
#Valores
x<-BASE1$height; breaks<-9
#Líneas de código fijas#
m<-min(x);M<-max(x); l<-(M-m)/breaks; cuts<- seq(m,M, l)
interv<-cut(x, cuts, include.lowest = TRUE, right = TRUE)
fa<- table(interv)
x<-c(m-l/2, cuts+l/2)
y<-c(0, fa, 0 )
df<-data.frame(x,y)
#Gráfico
ggplot(data = df, aes( x=x, y=y) ) +
geom_line(colour="#1F78B4") + geom_point(colour="#1F78B4")+
labs(size= "",
x = "Altura (cm)",
y = "Total de jugadores",
title = "Total de jugadores según altura. Barcelona y Real Madrid 2019-2020.")+
theme(panel.background = element_rect(fill='transparent', color="black"))
5.4 Distribuciones acumuladas
#Valores
x<-BASE1$height; breaks<-9
#Líneas de código fijas#
m<-min(x);M<-max(x); l<-(M-m)/breaks; cuts<- seq(m,M, l)
interv<-cut(x, cuts, include.lowest =TRUE, right = TRUE)
fa<- table(interv)
x<-cuts
y<-c(0, cumsum(fa) )
df<-data.frame(x,y)
#Gráfico
ggplot(data = df, aes( x=x, y=y) ) +
geom_line(colour="#1F78B4") + geom_point(colour="#1F78B4")+
labs(size= "",
x = "Altura (cm)",
y = "Total acumulado de jugadores",
title = "Total acumulado de jugadores según altura. Barcelona y Real Madrid 2019-2020.")+
theme(panel.background = element_rect(fill='transparent', color="black"))